
Demystifying GraphQL: An Exploration of Its Benefits, Practical Applications, and Challenges
GraphQL is an often misunderstood framework that went from being one of the most popular development innovations to an unfairly maligned one. In truth it has probably gotten over the initial wave of hype and misuse and found its rightful niche. As a Senior Software Development Engineer at Amazon, I spent a lot of the last year working with it and aim to explain through my experiences. Namely how useful it can be when used correctly, and the issues it can bring when used wrong.
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries against your data. It was developed by Meta (then Facebook) in 2012 and open-sourced in 2015. It enables clients to request exactly the data they need, reducing over-fetching and under-fetching. Unlike REST, which relies on multiple endpoints for different resources, GraphQL operates through a single endpoint and allows clients to specify the shape of the response. Meta, the creators of graphQL have used this since 2012. Various other companies like Netflix, Shopify and PayPal also use graphQL and have published their reasoning and experiences in blogs. I’ll link some of these interesting real world use cases at the end of the article.
When should you use it?
Choosing a framework for any enterprise solution is an expensive one, and one we should strive to get right upfront. Thorough investigation and comparisons to alternatives should always be done. Keep in mind the educational cost when choosing a novel framework like graphQL, if your team/company does not already use it. Data modeling and resolution in graphQL requires a slightly different mindset to traditional REST applications. Knowing how the framework handles query complexity is a key factor. Every new team member, or anyone working on this codebase will have to ramp up on a new framework. These are real world costs, so ensure graphQL solves a problem before choosing it as a solution.
That being said, I do think there are some initial questions that can help you begin the decision making process. You should use graphQL if one of more of the following is true :
- You have multiple clients, or expect to grow to multiple clients with various use cases.
- It’s important to note here that graphQL is not about handling scale. If you have various clients that need the same information, graphQL does nothing better than REST APIs
- Your clients innovate and iterate rapidly, and would benefit from the flexibility graphQL will bring on the client side.
- You work at an enterprise scale, where data discovery / data access is a problem you’re looking to solve
- You have multiple divergent data sources
- This is especially important if the various data sources differ in latency, failure rate or any other critical metrics
- You vend data subsets with different permissions and privacy levels
- You have a clear idea of the relationships between the data you are looking to vend.
What benefit does it provide?
The primary benefit GraphQL provides is that it prevents over-fetching of data. This is when you collect a large set of information when the caller only needs a smaller set. This can happen in traditional REST applications where an API was originally designed for a specific use case or a specific client. Over time, more data, use cases and features are added to it. More clients start onboarding as the domain grows, each wanting to tweak the API slightly to meet their needs. This isn’t a bad thing, encouraging re-use and evolving over building novel solutions for each use case is more maintainable and allows for faster time to market. It’s better to set up to handle these cases, instead of avoiding it. GraphQL also helps with this scaling as it is self documenting. Instead of relying on API documentation to be up to date, graphQL uses introspection to allow clients to query the schema itself. Since there aren’t strict API request and response shapes, clients can update their queries as their requirements change while application owners can add to the schema as more data becomes available. These changes can happen safely without breaking / blocking each other. The benefits can be best explained using a real world use case.
Explained using an example
GraphQL is frequently used as monolithic graphQL where a single large graphQL application queries multiple DBs or performs its own business logic. This is how Meta uses it today. For this example I am going to assume the enterprise uses micro service architecture which is a fairly common practice today.
Let’s consider a use case for a healthcare provider network consisting of multiple data sources, including patient records, medical imaging, billing, and insurance claims, each managed by separate services and databases. Various clients—such as doctor portals, patient mobile apps, and insurance dashboards—require different combinations of this data, and each data source has strict permission requirements due to healthcare privacy regulations (e.g., HIPAA, GDPR).
We can assume a situation like this will have the following data sources:
Electronic Health Records (EHR) Database
- Stores patient history, prescriptions, allergies, and doctor notes.
- Access Control:
- Patients can access their own records.
- Doctors can access records of assigned patients.
- Insurance providers have no access.
Medical Imaging Service
- Stores X-rays, MRIs, and CT scans linked to patient records.
- Access Control:
- Radiologists and doctors can view assigned patient imaging.
- Patients can access their own images.
- Insurance providers can access imaging metadata (but not the actual images).
Billing & Claims Service
- Manages patient invoices, insurance claims, and payment status.
- Access Control:
- Patients can view their own billing history.
- Doctors have limited access to billing details related to their services.
- Insurance providers can access claims data but not medical history.
Appointment Scheduling Service (Database: Appointments & Availability)
- Handles doctor schedules and patient appointments.
- Access Control:
- Patients can view and book their own appointments.
- Doctors can view their own schedules and assigned patient appointments.
- Insurance providers have no access.
The situation can be visualized as follows:
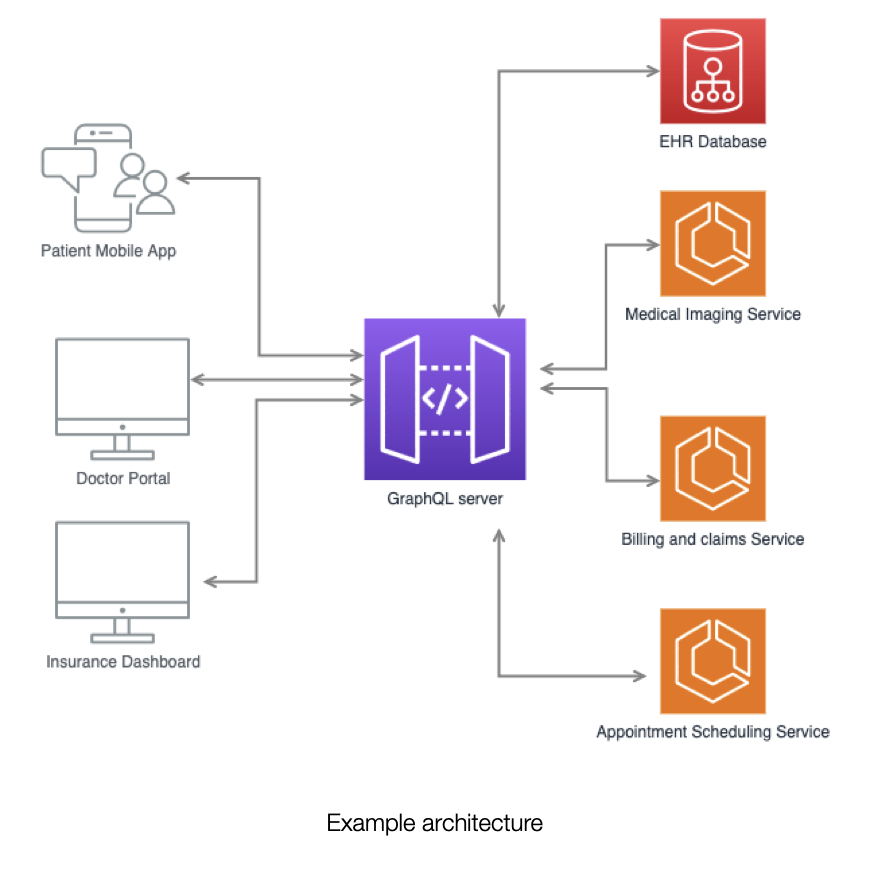
The application could have a schema that looks like follows (simplified)
type Query {
patients(type: PatientQueryType!): [Patient]
allAppointments(filter: AppointmentFilter): [Appointment]
availableDoctors: [Doctor]
insuranceClaims(id: ID): [InsuranceClaim]
billing: Billing
}
# Enum to define the type of patient query
enum PatientQueryType {
ME
ASSIGNED
ALL
}
type Patient {
id: ID!
name: String!
medicalHistory: MedicalHistory
latestImaging: ImagingReport
billing: Billing
insuranceClaims: [InsuranceClaim]
upcomingAppointments(filter: AppointmentFilter): [Appointment]
pastAppointments(filter: AppointmentFilter): [Appointment] filtering
vitalSigns: VitalSigns
}
type Appointment {
id: ID!
date: Date!
time: String!
location: String!
doctor: Doctor
patient: Patient
notes: String
}
input AppointmentFilter {
dateRange: DateRangeFilter
doctorId: ID
patientId: ID
status: AppointmentStatus
}
Schema Explained
This schema advertises any/all data that clients can request, while the graphQL application takes on the burden of permissions and effectively routing queries from these schemas to their respective data providers. Most data can be requested in bulk, or be filtered using query arguments. The schema is an important piece to get right, and there are various ways to organize the data. You want to take both the relationship between the data and the relationship between the data providers into account when designing the schema. The schema can be better explained with an example.
Consider a user of the patient app wants to get their upcoming appointments. The query will look as follows:
query {
patients(type: ME) {
id
name
upcomingAppointments(filter: { dateRange: { startDate: “2023-10-23”, endDate: “2023-10-29” } }) {
id
date
time
location
doctor {
id
name
specialty
}
}
}
}
In this case, the caller is not worried about billing or medical imaging information, and the graphQL application can dynamically decide to skip these calls.
You can consider other use cases where graphQL would help:
- If there is an issue with the appointment scheduling service, the application can successfully return billing information to the patient app, if that is all they’re requesting at the moment.
- Assume the Medical Imaging Service is either latency sensitive or an expensive compute operation. The GraphQl application will only make the imaging service call when the request query schema calls for it.
- The graphQL application can restrict permissions to certain domains so the doctor app can never request billing information or that the insurance dashboard can never access medical imaging.
GraphQL Advantages in This Setup
- Consolidated Data Access Across Services
- The patient mobile app needs access to EHR, medical imaging, billing, and appointments, but only for their own data.
- The doctor portal needs access to EHR, imaging, and appointments for assigned patients.
- The insurance dashboard requires access to claims and billing but not sensitive patient medical data.
- GraphQL allows each client to query only what they need in a single request.
- Fine-Grained Permission Control with GraphQL Resolvers
- GraphQL resolvers enforce role-based access control (RBAC) to ensure compliance with privacy regulations.
- Patients can query their own health records but not others’.
- Doctors can query assigned patient data but not billing details.
- Insurance providers can query claims and payments but not medical records.
- Efficient & Secure Data Retrieval
- There is a single data access layer where clients can find all information available. This can continue to evolve in the future and clients will easily be able to find new data.
- Instead of multiple REST calls to different services, clients make a single GraphQL request to retrieve structured data from multiple sources securely.
- Service calls / Database lookups will only be made if that specific data has been requested. You only pay the latency costs for the data you actually need
- Better scaling for both client and server:
- Clients can update their query, request new data or add filters as their use cases grow and requirements change
- Server can add fields and grow the data they offer without breaking existing queries.
Using GraphQL, each client can request only the data it needs, optimizing network efficiency while maintaining role-based access control (RBAC). This flexibility makes GraphQL an ideal solution for complex, multi-service healthcare ecosystems.
Pitfalls to avoid
Even in the right use cases, you will need to be careful to avoid some common issues, the most common being the “N+1 problem”. This boils down to inefficient data retrieval from dependencies. In a naive implementation consider the service calls if a caller requests allAppointments in the top level query along with upcoming appointments within the Patient schema.
Think of your data structure as a tree and avoid relationships between data at the same level of depth in a tree. You could result in a situation where a client requests nested queries that can crash the server. For example you could design a schema where An insurance claim has a Patient that has a list of insurance claims and you can see how a client can wreak havoc with a poorly designed query here.
GraphQL is schema driven and therefore does not have the concept of API versioning. Be very careful when making schema changes and follow pre established patterns of backward compatibility when making updates.
Finally when it comes to performance, graphQL does not work well with traditional HTTP caching. RESTful APIs use the URL which is the global unique identifier used to identify each GET request. This URL can be leveraged to build a cache. The URL serves as the key in the key-value pair in the cache storage and the response becomes the value. Unlike REST, GraphQL does not rely on URL-based responses, making traditional caching mechanisms less effective and requiring other solutions. Nevertheless, caching is still possible and there are other blogs that cover this. Federated GraphQL
The final thing I’d like to discuss is designing federated architecture using GraphQL. The above example already shows micro service interaction where graphQL acts as a gateway. This concept can be taken to the max with graphQL federation where each micro service is an independently managed graphQL service itself. Each service can define its own “sub graph” which is stitched into a massive schema that clients can query. The gateway service routes the requests to the correct subgraphs and it allows for scalable distributed domain ownership while offering a data aggregation layer for clients. This is the architecture that Netflix currently uses and is explained well here.
The overall setup will be very similar to the example in terms of inter service interaction. However each service being a sub graph is a great way to separate ownership between domain owners. Instead of a single team owning the entire schema, each subgraph can innovate and expand by themselves and the main graph automatically picks up updates. You can find more information on GraphQL federation here.
Conclusion
So there you have it. Hopefully this article has helped in understanding graphQL and knowing when to use it. GraphQL is a powerful and flexible API query language that addresses many of the limitations of REST by allowing clients to request exactly the data they need. Throughout this article, we’ve explored what GraphQL is, why it’s beneficial, and how it works through a practical example. We’ve also examined some of its potential pitfalls, such as the N+1 problem. While GraphQL provides greater efficiency, flexibility, and developer experience, it also requires careful query optimization, authorization handling, and performance monitoring to avoid common challenges. By understanding both its strengths and weaknesses, teams can make informed decisions about when and how to adopt GraphQL in their applications.
Whether you’re building a modern frontend experience, aggregating data from multiple sources, or simply looking for a more efficient way to handle APIs, GraphQL is a compelling option. With the right implementation practices, it can significantly enhance both API performance and developer productivity.
About the author:

Vignesh Kamath is a Senior Software Development Engineer at Amazon, with over 8 years of professional experience. He has received his Masters of Science in Computer Science from New York university.